About UniDBind
DNA-binding proteins are involved in many essential biological processes, and accurate identification of DNA-binding residues is critical for understanding protein function. However, existing computational methods are typically developed for either structure-resolved proteins or intrinsically disordered proteins, leading to fragmented modelling strategies. Moreover, many approaches rely on structural information or external predictors at inference time, limiting their applicability and preventing end-to-end prediction from sequence alone.
In this study, we propose UniDBind, an end-to-end sequence-based framework for unified prediction of DNA-binding proteins and residues across both structured and intrinsically disordered proteins. UniDBind integrates protein language model embeddings, evolutionary profiles, and physicochemical features to construct unified sequence representations. To capture heterogeneous binding mechanisms, we introduce a mechanism-aware mixture-of-experts architecture that adaptively models diverse DNA-binding patterns. During training, structure and disorder annotations are incorporated as auxiliary supervision to guide representation learning, while inference is performed using sequence-derived features only. Experimental results on structure-annotated and disorder-annotated datasets demonstrate that UniDBind achieves robust and consistent performance for both structured proteins and intrinsically disordered proteins, enabling end-to-end prediction of DNA-binding proteins and residues directly from sequence.
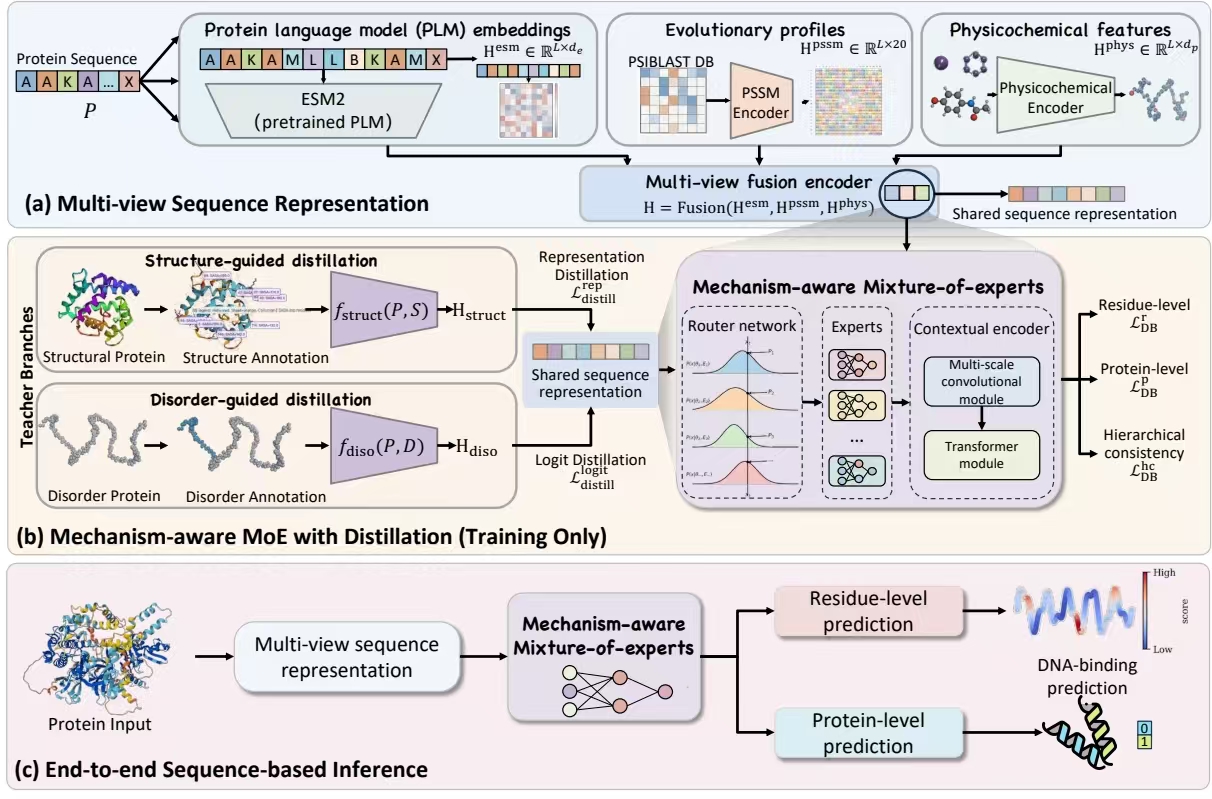
Overview of the UniDBind framework. The model integrates multi-view feature representation with a mechanism-aware mixture-of-experts architecture and distillation-based supervision. (a) Multi-view sequence representation constructed from protein language model embeddings, evolutionary profiles, and physicochemical features. (b) Mechanism-aware mixture-of-experts with distillation (training only), where auxiliary structure (SS and SASA) and disorder annotations provide complementary supervision. (c) End-to-end sequence-based inference enabling unified prediction of DNA-binding at residue and protein levels without requiring structural or disorder annotations.