iPromoter-2L2.0: a predictor for identifying promoters and their types by combining Smoothing Cutting Window algorithm and sequence-based features |
The benchmark dataset  constructed for identifying promoters and their types. It is formed by seven subsets:(1)
constructed for identifying promoters and their types. It is formed by seven subsets:(1) 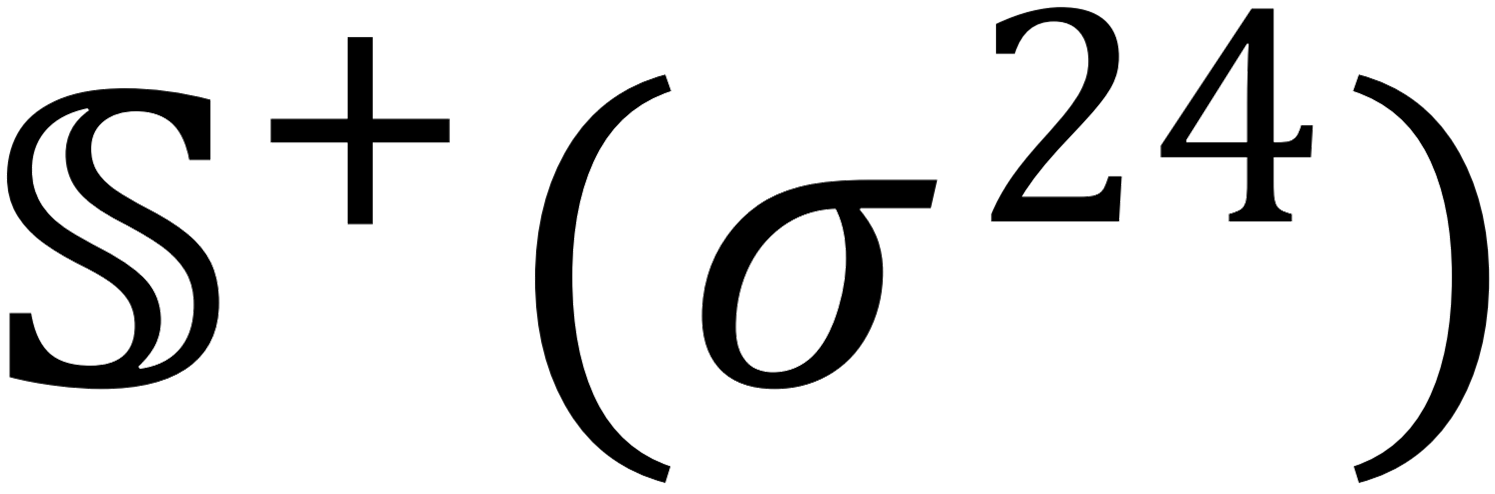 contains 484 σ24-promoter sequences; (2)
contains 484 σ24-promoter sequences; (2)  contains 134 σ28-promoter sequences; (3)
contains 134 σ28-promoter sequences; (3) 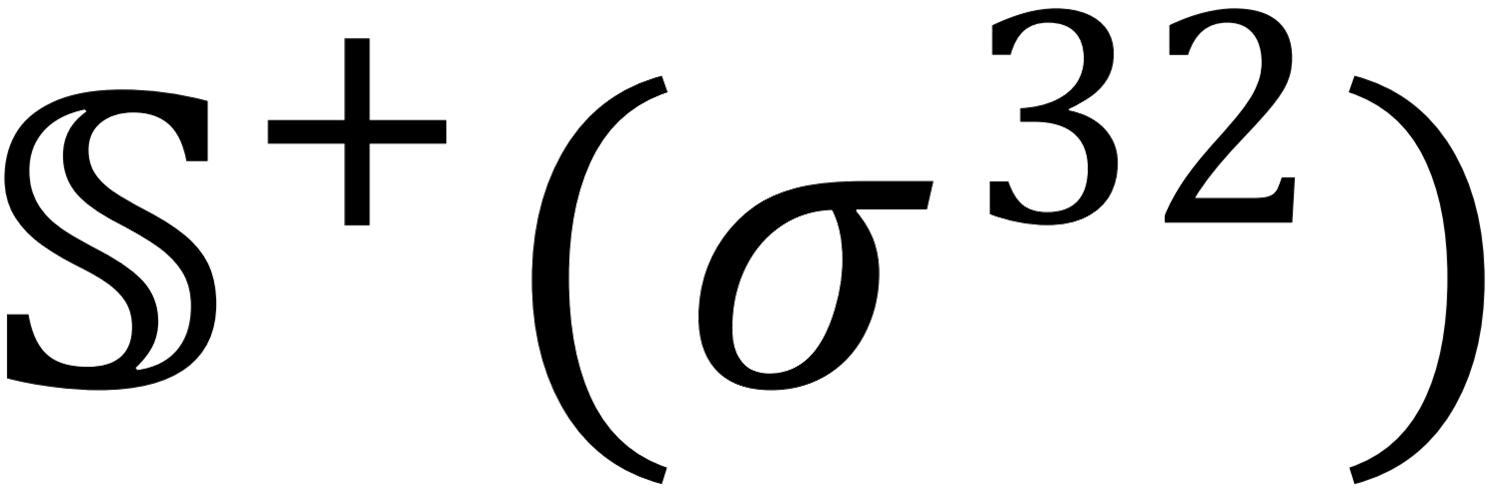 contains 291 σ32-promoter sequences; (4)
contains 291 σ32-promoter sequences; (4)  contains 163 σ38-promoter sequences; (5)
contains 163 σ38-promoter sequences; (5)  contains 94 σ54-promoter sequences; (6)
contains 94 σ54-promoter sequences; (6) 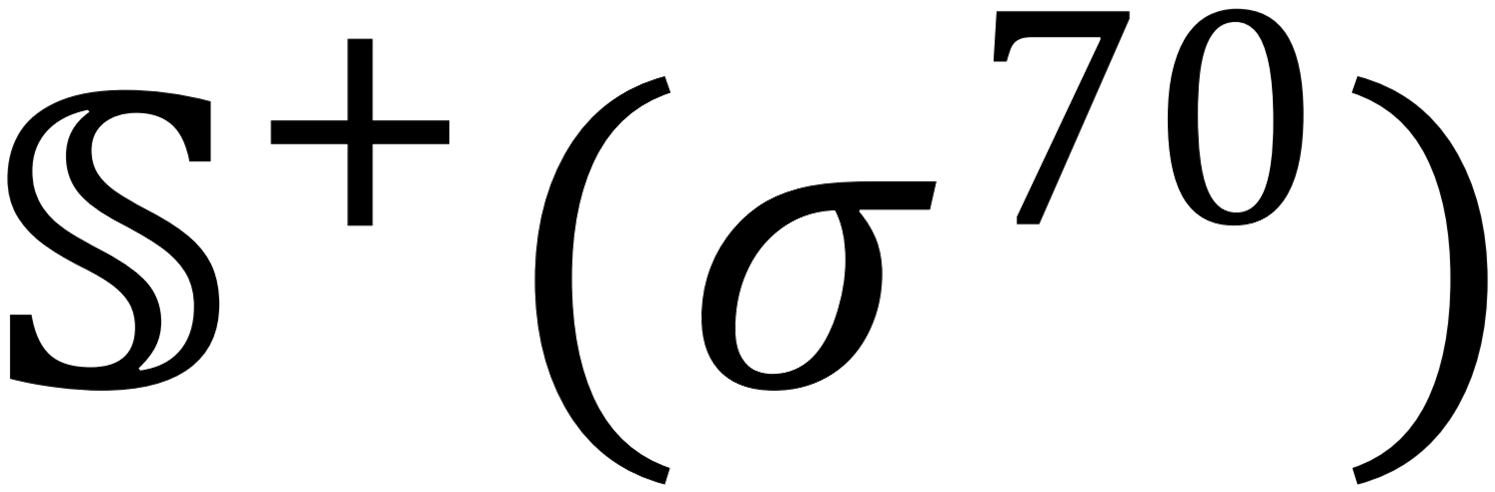 contains 1,694 σ70-promoter sequences; (7)
contains 1,694 σ70-promoter sequences; (7)  contains 2,860 non-promoter sequences. The length of each sample is 81bp. None of the sequences included here has ≥80% pairwise sequence identity to any other in a same subset. See Eq.1 and the relevant text for further explanation. The benchmark dataset can be downloaded from Supplementary Information S1(pdf,docx).
contains 2,860 non-promoter sequences. The length of each sample is 81bp. None of the sequences included here has ≥80% pairwise sequence identity to any other in a same subset. See Eq.1 and the relevant text for further explanation. The benchmark dataset can be downloaded from Supplementary Information S1(pdf,docx).