Abstract:
We propose KaMT, a knowledge-aligned multi-modal Transformer for molecular representation learning. The main contribution is a unified framework that jointly encodes molecular graph structure and physicochemical descriptors within a shared latent space, enabling consistent structural–biophysical representation. KaMT introduces a dual-stream architecture that separates structural and property-aware encoding while enforcing cross-modal alignment, improving the expressiveness of molecular embeddings. In addition, it incorporates knowledge-guided representation learning to better capture chemically relevant features and enhance generalization across structurally diverse compounds. Overall, KaMT provides a general molecular learning framework that integrates structural and biophysical information for improved representation quality.
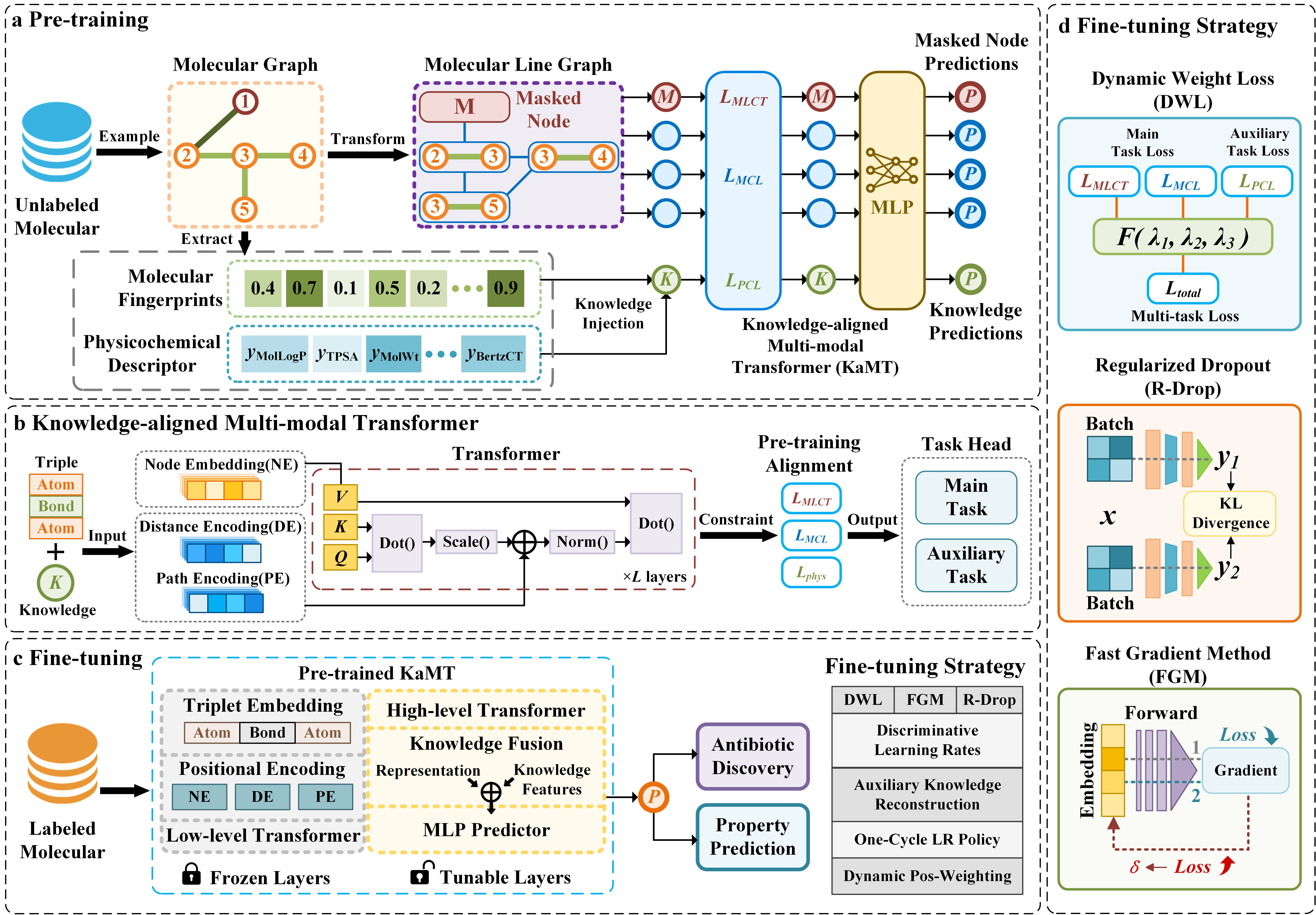
The flowchart of KaMT model is shown in Figure 1
Figure 1.
Schematic overview of the KaMT framework.
(a) Pre-training with biophysical descriptors and MLG-based masked node prediction.
(b) Transformer architecture integrating node, distance, and path encodings under cross-modal alignment.
(c) Fine-tuning framework for antibiotic screening tasks.
(d) Robust optimization using DWL, R-Drop, and FGM.